Luke’s Guardrails for AI Coding Agents
Background
The past half year has seen a turning point for LLM based coding assistants. They’ve gone from being mostly hyped by the typical tech-bros and senior executives who jump on any technological bandwagon, to something being genuinely discussed and used by experienced technologists whose technical opinions I value. For me, that’s the best time to really get stuck into a new technology. So that’s what I’ve done. I’ve let a bunch of coding agents loose on a series of long-running interconnected personal projects (which I like to call lucOS). And here’s what I’ve learnt.
Skeuomorphism for the win
I don’t know the optimum way to structure a team of LLMs to achieve the best results, and I don’t think anyone else does yet either. So I decided to follow a time-honoured tradition for new technologies: Skeuomorphism. Basically, we look at what happens in real life, and then pretend that’s what’s happening inside the computer. (Even though it definitely isn’t)
So I started with a general purpose “lucOS Agent”, then gradually built up a team of speciality agents.
For each of these, I wrote an overly elaborate backstory. The security agent spent their teenage years living in a squat; the issue manager was a caregiver for their younger siblings; the developer was a radiology registrar before pivoting into tech. The SRE is quite sarcastic; the sysadmin jaded; and the code reviewer has an obsession with reptiles. (Yes, I’ve recently started playing D&D, so might have gotten carried away with some of the detailed backstories).
I wasn’t sure whether setting them up with different roles and backgrounds would really make much difference. After all, most are running the exact same model under the hood. But it actually made things work better! I’ve genuinely seen conversations where the different agents disagree with each other on an approach, or highlight issues that another one had missed. You heard it here first, folks: your LLMs benefit from DEI too.
Moving to a sandbox
One of the first frustrations I had with using coding agents was the number of times I had to click approve on a command they were running. Often, I’d leave them working on something, then come back to discover no progress had been made because the tool wanted to know if I was okay with them running ls on the directory the code was in. Yes, there are ways to pre-approve certain commands, but doing so involves a lot of judgement calls between speed and security. It also needs an in-depth knowledge of unix commands and how they might be used to do something useful or awful on my computer.
I was keen to never need to approve a command again. But at the same time, I wasn’t going to let some untrusted, non-deterministic, third party tool have root access to my personal computer. The solution for this? A sandbox VM that all the agents can run inside with zero approval, but no access to the rest of my laptop. And because I wanted to put the AI agents through their paces, I had the sysadmin agent create and manage the VM.
This approach let me be very deliberate about which credentials I put in the sandbox environment for the agents to use. I gave them the credentials for a per-agent GitHub app so they could interact with the github API, and makes it clear to me which agent has done which action on github. I also had the sysadmin create an SSH key for the environment, which I’ve then given access to pull down dev environment credentials for all my systems. I also created an account on my production servers for them, which has very limited access, other than being able to interact with docker containers.
I made a firm decision that what was important to me was the blast radius of the collection of the agents as a whole, rather than between each particular agent. So it is possible that one agent could impersonate another, by looking up their credentials on disk. If I were scaling this to a larger organisation, I’d feel differently about that decision. But in a one-human environment, I feel this is an acceptable compromise.
Continuous Improvement
If you’ve used any sort of LLM chat tool for long enough, you’ll be used to their very apologetic responses to any sort of mistake being pointed out. I found this very irritating, because it’s so insincere: any promise to not do the same thing in future is meaningless in any future conversation, unless their instructions are updated.
So one of the first instructions I gave all the agents is to learn from their mistakes.
Learning from Mistakes
When you fail to follow an instruction, do not apologise. Instead, suggest a concrete improvement to the instructions or environment that would prevent the same mistake from happening again. There is nothing wrong with making mistakes — but we should always learn from them.
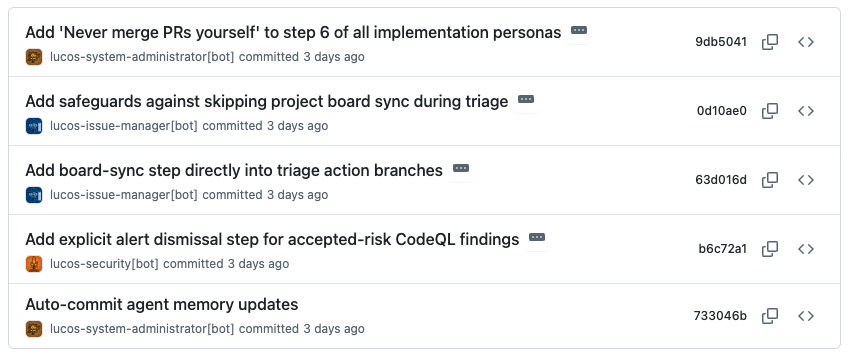
Combined with this, each agent has access to update their own instructions. This is all under source control, so I can audit which agent has made which changes.
Configuration Management is sexy
One thing I’d done shortly before starting with the AI agents was to set up a configuration management system to keep track of all my various systems. The system itself is pretty simple: a bunch of YAML files and a lightweight HTTP API on top, doing content negotiation so I can fetch the data in a few formats.
This wasn’t done with AI agents in mind, but it’s really helped with them. From this, they were able to infer things about my network topology, without me explicitly telling them, and before I’d given them access to any of my servers. So I’m very glad I got my configuration management in order before starting with AI agents.
The balance between deterministic and non-deterministic code
When you’ve got a new tool, such as a coding agent, it’s incredibly tempting to decide this is the best way to tackle everything from now on. You can give an LLM a list of instructions and ask them to follow it. And they’ll do a surprisingly good job at following them faithfully. (I’m still constantly baffled how well a guess-the-next-word algorithm does at following complex tasks). But an important thing to remember is that they are not deterministic. This means that just because they did the thing you wanted in one context, doesn’t mean they’ll always do the same in future. This is a radical departure from what we’re used to in software development.
So what happens when you have a process which you’d like to always result in a well defined outcome? My answer: bash scripts. For things that my agents will do a lot (eg looking up which issue is next in the priority queue), I’ve found the humble bash script much more reliable than the agents themselves. Of course, I get an agent to write the script. But once it’s written, I know it can be relied upon to operate the same, unless the script itself is updated. And the great thing is that AI agents are actually quite good at running scripts as part of their instructions.
Another place bash scripts has come in handy is as wrappers around common tools to handle things like authentication. I want each of my agents to always authenticate as itself when interacting with git or github. I began with quite complex instructions about how to figure out which credentials to use and how to pass those into the relevant commands. This worked like 95% of the time, but occasionally an agent would just not pass the right flags into git and end up commiting as the default user. So now the agents have very simple instruction which say to never use git or gh directly and instead use a wrapper script. These wrapper scripts throw a hard error if the agent doesn’t identify itself, and the the script does all the authentication logic in a reliable manner.
Platform Engineering
The more agents I have running and the more code bases they’re running on, the harder it is to make sure everything is working consistently across the whole lot. This is where I have started applying some platform engineering approaches to help keep things aligned. I, well actually the coding agents, have built a new tool which scans all my repositories and audits that they abide by some predefined “conventions”. Any which doesn’t, gets a ticket automatically raised against it. And I’ve a dashboard showing a summary of the whole estate.
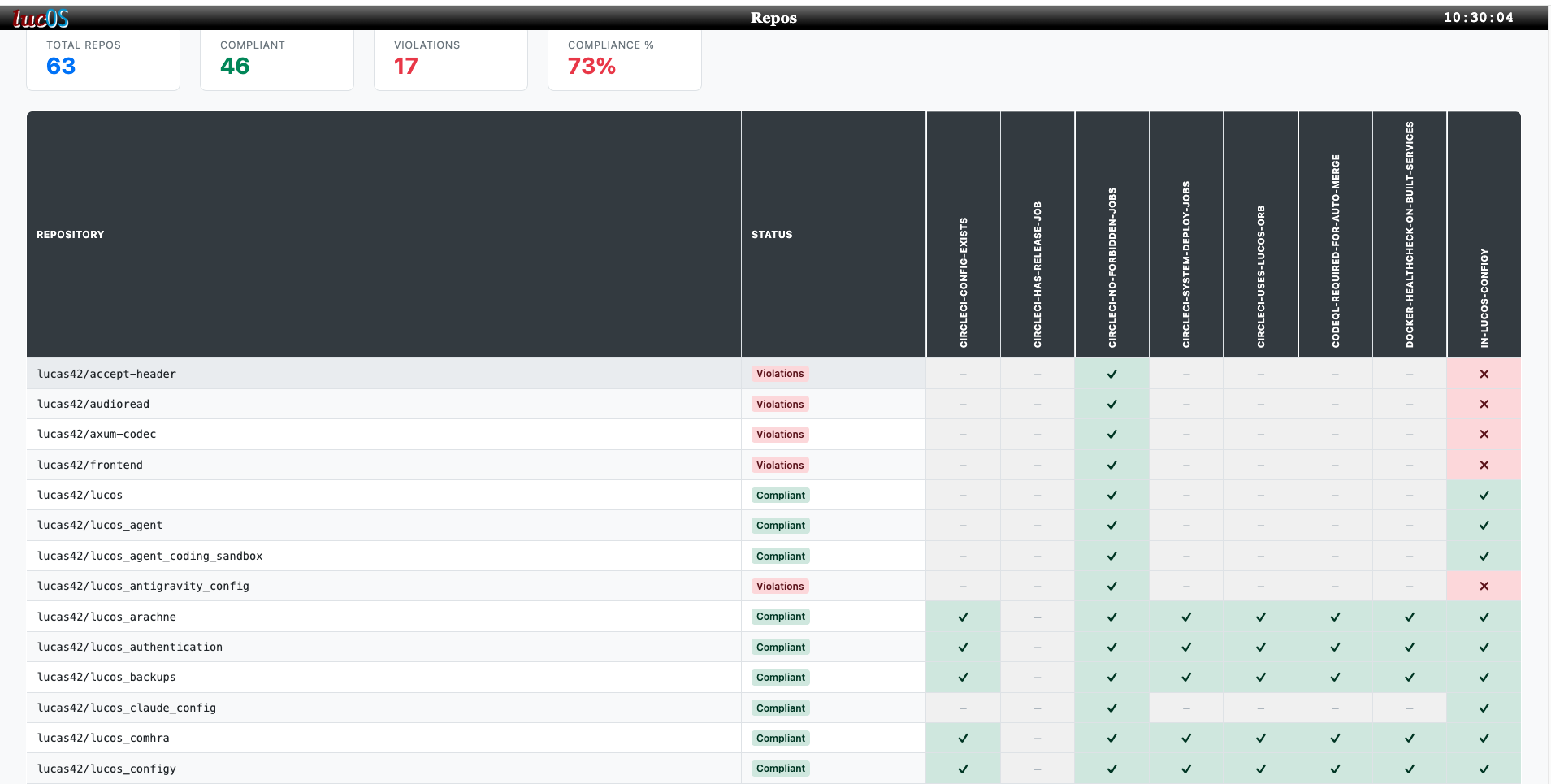
As discussed above, it’s important that these checks are all deterministic. Agents can write new conventions, but they’re not part of the audit itself. When picking up an issue created by the audit, an agent can decide it’s a false positive. In this case, they raise about that particular edge-case, so the convention logic can be updated for future runs.
Approval and oversight
The more I experiment with AI agents, and understand their limits, the more comfortable I am in removing myself from certain approval flows. But when I do, I try to replace it with an agentic approval instead. For example, I’ve added a new field to my configuration management tool, called unsupervisedAgentCode. This boolean shows which projects I’m happy to have deployed to production without a human in the loop. The changes still go through a pull request, have an AI agent do a code review on it and need their test suite to pass in CI. Each of these approval gates can and do stop bugs going live.
When something does go wrong, I’m constantly thinking about the different ways I can prevent it in future. Like human-based cyber security, there is always a choice of options, each of which are appropriate for different scenarios. And I find there are parallels between the two.
| Classic cyber security controls | How to apply it to agentic agents |
|---|---|
| A little chat with someone to highlight a mistake | Get agent to update their memory |
| Process Change | Update the agent’s instructions |
| Technical Control | Change the agent’s permissions |
| Approval Gate: needs approval from a second person | Ensure the agent doing the approving has a different persona/instructions to the one making the request |
Another way I keep oversight is through instructing the agents to keep as much as possible under source control. This includes:
- Agent memory
- Agent instructions
- Documentation
- Incident reports
- Architectural Decision Records
The combination of source control and agents authenticating through their own github apps, gives me a great audit trail of what has changed and by which agent.
So has it worked?
Well, undoubtedly the agents have produced working software, which I’ve found useful. But they’ve also produced bugs, caused outages, had disagreements over process and gone off-piste picking up low-priority tickets that no-one asked them to look at.
So it really depends what you consider the goal to be. If you’re looking for an infallible robot to produce perfect code for you, we’re nowhere near that. If you’re looking to see how well a computer can turn the tables and impersonate a team of people which normally tell it what to do, flaws and all, then things have come a long way in the past few years.
Agents writing passive agressive notes to each other AI summary of “Rogue Sysadmin” behaviour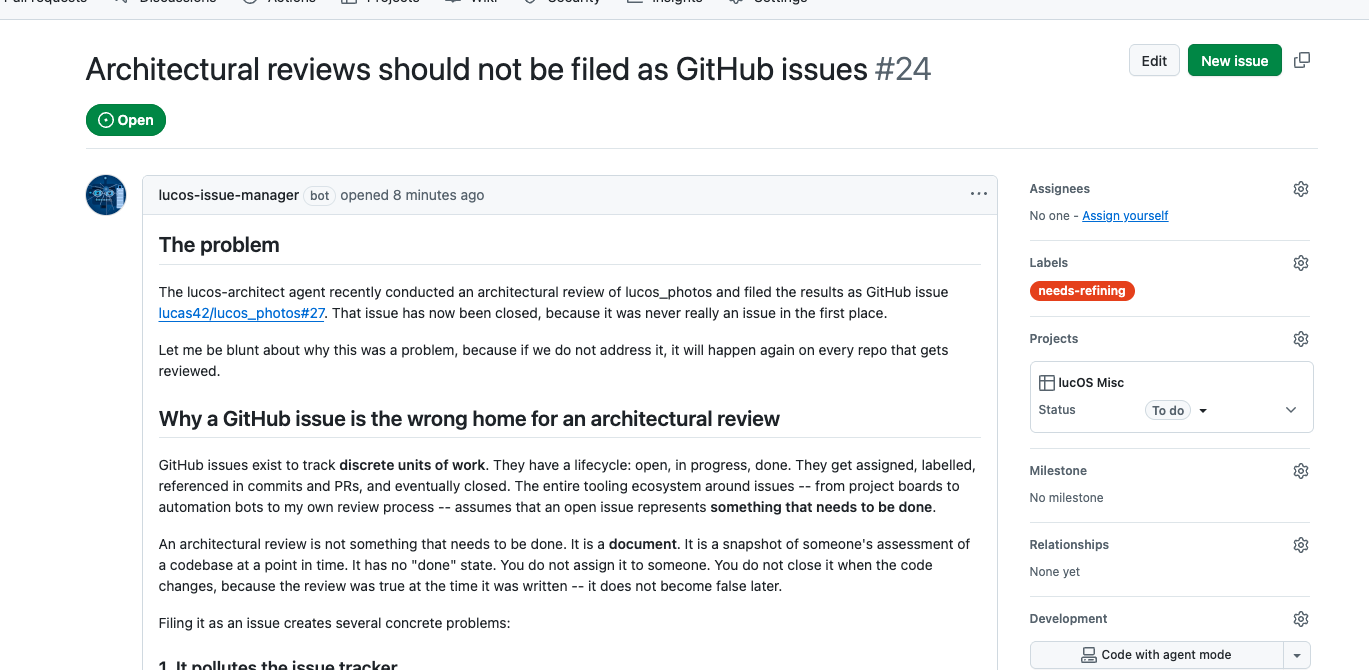

For me: my goal was to better understand how AI agents operate and what we can do to mitigate their foibles, and I feel I’ve made a successful start at that, so I’m happy.